892 浏览本文是一篇教育论文。利用机器学习建立流动儿童问题行为的预测模型是可行的,具有较强的预测能力,主要体现在通过三种不同的算法模型可以获得更一致、更高的预测性能。
1文献综述
研究总结1.1问题行为。
1.1.1概念定义。
(1)流动儿童。
根据教育部《2019年全国教育发展统计公报》,流动儿童(又称城市农民工子女)是指在其他省(区、市)、省外县(区)注册的适龄儿童和青少年。
(2)问题行为。
问题行为(Problembehaviors)是指个人表现出的异常行为(林崇德、杨志良、黄希庭、2003),以及学者吕勤、陈会昌、王莉(2003)认为儿童问题行为是指偏离、不符合正常标准的行为,是阻碍儿童身心正常健康发展的行为。由此可见,问题行为是对儿童身心发展的不利行为。问题行为可分为内化问题行为和外化问题行为。内化问题行为主要涉及情绪障碍或障碍,如抑郁、焦虑、孤僻、退缩等情绪问题。外化问题是指行为障碍或障碍,主要包括各种形式的行为障碍、过失、攻击和违法违纪行为(Achenbach、Mconaughy、&Howell、1987)。本研究将主要探讨儿童的外化问题行为。
1.1.2理论基础。
(1)相对剥夺理论(relativeprivationtheory)
相对剥夺理论认为,弱势群体的自我感受与参考群体有着非常重要的关系,这种感觉通常来自于自己与他人的比较(Schulze&Krtschmer-hahn,2014)。例如,流动儿童在流动地点感知到的歧视感与当地居民有很大关系。这一理论起源于美国士兵的研究,如Stouffer。后来,Merton等人在此基础上将剥夺的相对性与参考群体的概念联系起来(Merton&Kitt,1950),并正式提出了相对剥夺理论,即如果个人与他人进行比较,发现自己处于不利地位,个人就会感到被剥夺。这种剥夺会带来一系列负面情绪(如不满和抑郁)和问题行为(如暴力和物质滥用)。后续研究发现,当人们发现自己和他人之间的差异时,就会产生积极或消极的情绪反应和行为(buunk,collins,&taylor,1999;smith,2000)。如果有研究发现,长期的歧视感会导致个人自卑。
(2)一般压力理论(Generalstraintheory)
Agnew(1992)的一般压力理论认为,个人和家庭、学校和邻居之间的负面/不利关系所产生的压力在达到一定阈值水平后会对个人的犯罪行为产生积累影响,即强调负面经历对个人的压力,从而应对或缓解压力,导致个人容易出现问题。此外,随着这种积累的影响,问题行为的负面后果将变得更加严重。Agnew(2006)后来的研究还表明,与高社会阶层相比,低社会阶层的个人可能会经历更多的压力,导致更多的犯罪活动
...
1.2机器学习在心理健康领域的研究总结。
1.2.1概念定义。
机器学习(Machinelearning)是一个自动分析、判断或预测新未知数据的过程(Cabitza&Banfi,2018年;Sendersetal.,2018年)。机器学习之父汤姆·米切尔对机器学习的正式定义是:假设使用P(Performance)来评估某个任务T(Task)上计算机程序的性能。如果该程序通过使用E(Experince)来提高T任务中的P性能,则认为该程序已经学习了E(Mitchell,1997)。
1.2.2机器学习算法。
机器学习算法大致可分为三类:(1)监督学习;(2)半监督学习;(3)无监督学习。监督学习是通过训练获得特征(预测变量)和标签(结果变量)之间的关系来判断新数据。使用标签数据训练模型,可以预测新数据的标签。例如,机器学习模型可以通过使用边缘人格障碍患者和成功治愈边缘人格障碍患者的FMRI脑成像数据自动识别机器学习模型,以预测边缘人格障碍患者的治疗效果(Schmitgen、Niedfeld、&Schmit,2019)。其次,监督学习分为分类算法和回归算法。分类算法一般包括决策树、简单贝叶斯(Na)vebayes)支持向量机(supportvectormachine)、K近邻(k-nearestneghbor)、逻辑回归(Logisticressive)、随机森林(randomforest)等。回归算法一般包括岭回归和Lasso回归。
半监督学习介于监督学习和半监督学习之间,通过在有或无标签的数据中执行监督或无监督的学习任务来判断新数据。半监督学习的常用算法包括半监督支持向量机等。
无监督学习是通过培训获取无特征和标签数据之间的关系,从而判断新数据,即通过对无标签数据进行聚类,从而在数据中找到新的潜在集群。例如,在社交论坛上广泛收集和分析有关心理疾病的话题,以找到可能的有用信息,如最常见的预测内容(Thorstad&Wolff,2019)。无监督学习的常用算法是K平均值(K-meansclusteringalgorithm)和神经网络(Neuraletworks)。
...............................
2 问题提出
2.1 现有研究的局限
从研究内容看,已有多数研究主要关注一个或多个变量对流动儿童问题行为的预测作用,如有研究者探讨情绪调节对青少年问题行为的影响,发现情绪调节的异常或困难是造成儿童问题行为的主要原因(Heleniak, Jenness, Vander, McCauley, & McLaughlin, 2016);还有研究探讨了学校适应对流动儿童问题行为的影响,其发现流动儿童问题行为与学校适应存在显著的负相关,并且学校适应的各个维度都在一定程度上对流动儿童问题行为有负向的预测作用(王中会,石雪玉,2015)。而面对多个预测变量时,常常关注流动儿童问题行为影响因素的作用机制和边界调节的问题,研究方法常包括中介或调节效应、结构方程模型及多元回归,如有研究建立了一个有调节的中介模型以考察同伴侵害在儿童问题行为和父亲的拒绝教养方式之间的中介作用,同时也考察了该过程是否会有冲动的调节作用(黄林辉等,2019)。
然而,预测流动儿童问题行为的因素众多,如何从众多因素中选出更具有关键性的影响因素,以便基于关键影响因素进行更有针对性、实效性的心理辅导和干预,这是众多研究者不断探索的核心问题之一。
机器学习方法为解决该问题提供了有益的路径。以往的研究方法和技术(如多元回归分析等),能探讨的变量有限,无法研究太多的变量,当超过十个以上的变量时就难以处理,模型也会变得十分复杂(Jun et al., 2019;王衍鲁,张利会,张淑洁,石洁茹,王鹏,2017)。且传统的心理统计方法建立在数据正态分布假设基础之上,假设变量之间是线性关系,这可能会丢失数据的真实信息。本研究中的问题行为在青少年群体中则属于偏态分布,因此基于正态分布的假设检验方法则是不合适的。同时,样本群体的显著性检验通常是在两种可能的结果(零假设和备择假设)之间做决定,如此的话只是在回答一个孤立的统计问题(Randal, William, Zairah, Varik, & Moore, 2018),而且基于 P 值的显著性检验正面临重复危机,即研究结果的不可复制性(Dwyer, Falkai, & Koutsouleris, 2018),并且通过显著的群体差异并不能建立预测模型。由于较低的效果量,具有统计意义的变量并不一定对预测有作用。当与其他变量结合使用时,一些研究证明不显著的变量也可能会变得很重要(Dinga et al., 2018)。
..........................
2.2 本研究的改进
(1)本研究使用机器学习技术可以实现对问题行为的准确预测,机器学习技术旨在进行预测和建立预测模型,因此,已有大量研究证明机器学习的预测的准确率比传统统计方法更高。同时,机器学习的交叉验证技术能够减少重复危机的威胁;并且使预测模型具有更强的泛化能力,从而使模型的更加稳健和可靠。
(2)本研究利用机器学习技术可处理更多的预测变量,即使是多维相关数据也可处理,如对问题行为产生影响的变量之间有的可能是存在多重共线性的;并且机器学习对数据集的假设较少,如正态性和线性假设,即使是非线性数据也能够很好地进行处理。
理论意义:对研究和了解流动儿童问题行为的产生机制将会有极大的帮助,充实有关儿童问题行为的理论研究,扩展有关儿童问题行为的理论基础,从而了解到问题行为可能是一个复杂的多因素共同作用的结果。同时,还能够为后续实践工作中,流动儿童问题行为的预防和干预提供科学的理论指导。
实践意义:就社会而言,建立流动儿童的问题行为预测模型,能够及时发现流动儿童问题行为的存在,从而采用有关措施来进行提前干预,以减少未来可能产生的社会冲突和违法犯罪行为,对和谐社会的构建也具有重大意义。就家庭和学校而言,能够起到及时的预防和干预作用,从而在最大程度上避免流动儿童问题行为的发生和发展,对于创造良好的生活和学习氛围以及和谐的人际关系具有重要实践意义。就流动儿童个体而言,及早的识别和干预可能存在的问题行为,对维护流动儿童自身的身心健康发展也具有重要意义。
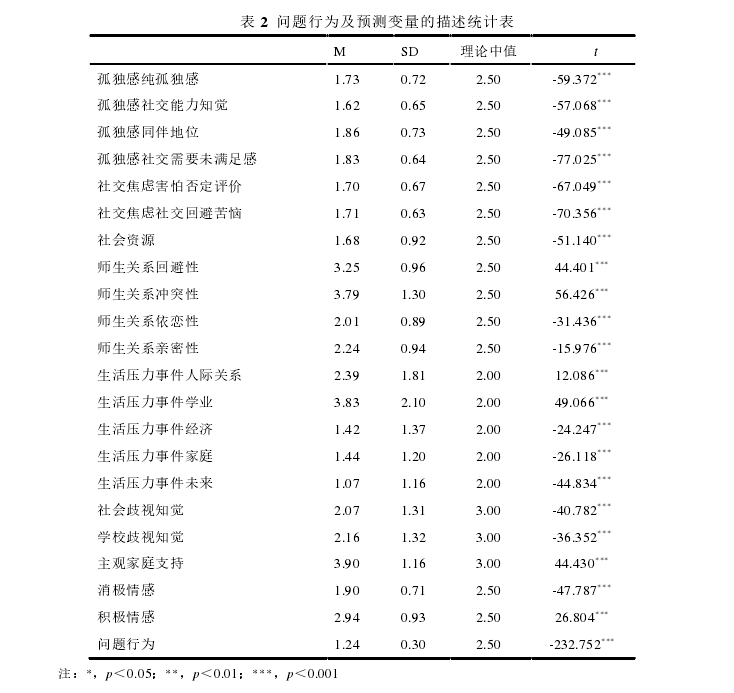
表 2 问题行为及预测变量的描述统计表
...................................
3 研究方法 ................................................... 12
3.1 研究对象 ....................................................... 12
3.2 研究工具 ........................................... 12
4 结果 .................................................. 17
4.1 共同方法偏差检验 .................................................. 17
4.2 各变量的总体状况分析 ............................................ 17
5 讨论 ......................................... 26
5.1 各变量的总体状况分析 ............................................. 26
5.2 机器学习的预测分析 ........................................ 28
5.3 研究的局限与不足 ...................................... 30
6 教育建议
6.1 家庭层面
在家庭层面,由于不可抗因素导致的流动的经历或许不可避免,但良好的亲子关系和家庭氛围却是能够主动创造的,因此,学校和教师可通过家校合作等形式,及时发现流动儿童的不适应性行为,可在最大程度上减少流动儿童的问题行为。
(1)可通过开展一系列知识科普和简单的培训工作,让家长充分了解流动儿童身心发展规律,来到流入地可能产生哪些心理不适的情况以及家长应如何应对。
(2)告知家长应同学校的老师互相保持密切的联系,从而获得更多儿童在家校的学习和生活情况,以期最早的发现问题和解决问题。
(3)学校可通过定期开展家长会、家长开放日和家访等活动,使家长更加了解流动儿童的校园生活,进一步拉近与流动儿童的距离,增进亲子关系,缓解流动儿童的校园适应不良。

图 1 问题行为在年级上的特点
................................
7 结论
(1)流动儿童问题行为的影响因素是多方面和多因素的,其中重要因素包括生活压力事件中的人际关系、家庭压力和学习压力维度、消极情感、师生关系中的亲密性和冲突性维度、主观家庭支持、孤独感中的纯孤独感和同伴地位维度、家庭社会经济地位、积极情感。
(2)利用机器学习建立流动儿童问题行为的预测模型是可行的且预测能力较强的,主要体现在通过三种不同的算法模型可以得出较为一致且较高的预测性能。
参考文献(略)





{kind=link}